Code
# Installation (à faire une seule fois)
install.packages("lubridate")
# Chargement
library(lubridate)Les analyses de données commerciales, financières ou marketing impliquent presque toujours une dimension temporelle. Savoir manipuler efficacement les dates est donc une compétence indispensable pour tout analyste de données utilisant R. Dans ce tutoriel, nous allons :
lubridate# Installation (à faire une seule fois)
install.packages("lubridate")
# Chargement
library(lubridate)La force de lubridate réside dans sa syntaxe intuitive. Pour créer une date, il suffit d’utiliser une fonction dont le nom correspond à l’ordre des éléments.
# Format année-mois-jour
ymd("2025-02-25")[1] "2025-02-25"# Format jour-mois-année
dmy("25-02-2025")[1] "2025-02-25"# Format mois-jour-année (format américain)
mdy("02/25/2025")[1] "2025-02-25"# Fonctionne avec différents séparateurs ou sans
ymd("2025.02.25")[1] "2025-02-25"ymd("20250225")[1] "2025-02-25"Les fonctions de création de date acceptent de nombreux formats et séparateurs, ce qui facilite le nettoyage des données importées de diverses sources.
Pour inclure l’heure, ajoutez simplement le suffixe correspondant :
# Année-mois-jour heure-minute-seconde
ymd_hms("2025-02-25 14:30:45")[1] "2025-02-25 14:30:45 UTC"# Jour-mois-année heure-minute
dmy_hm("25-02-2025 14:30")[1] "2025-02-25 14:30:00 UTC"# Création d'une date
ma_date <- ymd("2025-02-25")
# Extraction des composants
year(ma_date) # Année[1] 2025month(ma_date) # Mois (numérique)[1] 2month(ma_date, label = TRUE, abbr = FALSE) # Nom du mois complet[1] février
12 Levels: janvier < février < mars < avril < mai < juin < juillet < ... < décembreday(ma_date) # Jour du mois[1] 25wday(ma_date, label = TRUE, week_start = 1) # Jour de la semaine (débutant lundi)[1] mar\\.
Levels: lun\\. < mar\\. < mer\\. < jeu\\. < ven\\. < sam\\. < dim\\.quarter(ma_date) # Trimestre[1] 1# Copier la date pour démonstration
date_modifiee <- ma_date
# Modification de l'année
year(date_modifiee) <- 2026
date_modifiee[1] "2026-02-25"# Modification du mois (en une ligne)
date_modifiee <- date_modifiee %>% month(5)
date_modifiee[1] févr
12 Levels: janv < févr < mars < avr < mai < juin < juil < août < ... < décL’un des grands avantages de lubridate est la simplicité des opérations arithmétiques :
ma_date <- ymd("2025-02-25")
# Ajouter différentes unités de temps
ma_date + days(10)[1] "2025-03-07"ma_date + weeks(2)[1] "2025-03-11"ma_date + months(3)[1] "2025-05-25"ma_date + years(1)[1] "2026-02-25"# Combinaison d'opérations
ma_date + days(5) + months(1)[1] "2025-04-02"# Différence entre deux dates
date1 <- ymd("2025-01-15")
date2 <- ymd("2025-03-25")
interval <- interval(date1, date2)
as.period(interval)[1] "2m 10d 0H 0M 0S"Attention à la différence entre period et duration ! - months(1) (période) : ajoute un mois calendaire (variable selon le mois) - dmonths(1) (durée) : ajoute exactement 30.44 jours
# Démonstration de la différence
ymd("2025-01-31") + months(1) # Respecte le calendrier[1] NAymd("2025-01-31") + dmonths(1) # Ajoute une durée fixe[1] "2025-03-02 10:30:00 UTC"Maintenant, appliquons ces connaissances à un projet concret. Nous allons analyser les données de vente d’une chaîne de magasins fictive pour identifier les tendances saisonnières et les opportunités commerciales.
Commençons par créer un jeu de données réaliste :
# Fonction pour générer des ventes avec patterns saisonniers
generer_ventes <- function(n_jours, date_debut) {
set.seed(123)
# Séquence de dates
dates <- seq(ymd(date_debut), ymd(date_debut) + days(n_jours - 1), by = "day")
# Tendance générale à la hausse
tendance <- seq(1, n_jours) * 5
# Saisonnalité hebdomadaire (weekend +)
saisonnalite_hebdo <- ifelse(wday(dates) %in% c(1, 7), 2000, 0)
# Saisonnalité mensuelle (fin de mois +)
saisonnalite_mensuelle <- ifelse(day(dates) >= 25, 1000, 0)
# Saisonnalité annuelle (été et Noël +)
mois <- month(dates)
saisonnalite_annuelle <- case_when(
mois %in% c(7, 8) ~ 3000, # Été
mois == 12 ~ 5000, # Noël
mois == 1 ~ -1000, # Janvier (après Noël)
TRUE ~ 0
)
# Valeurs de base avec bruit aléatoire
base <- 10000
bruit <- rnorm(n_jours, mean = 0, sd = 1000)
# Génération des ventes journalières
ventes <- base + tendance + saisonnalite_hebdo + saisonnalite_mensuelle +
saisonnalite_annuelle + bruit
# Création du dataframe
data.frame(
date = dates,
ventes = round(pmax(ventes, 0)),
magasin = sample(c("Paris", "Lyon", "Marseille", "Bordeaux", "Lille"), n_jours, replace = TRUE)
)
}
# Génération de deux ans de données
ventes <- generer_ventes(730, "2023-01-01")
# Aperçu des données
head(ventes) date ventes magasin
1 2023-01-01 10445 Paris
2 2023-01-02 8780 Bordeaux
3 2023-01-03 10574 Lille
4 2023-01-04 9091 Lyon
5 2023-01-05 9154 Paris
6 2023-01-06 10745 BordeauxPréparons les données en ajoutant des dimensions temporelles utiles :
# Enrichissement des données avec composantes temporelles
ventes_enrichies <- ventes %>%
mutate(
annee = year(date),
mois = month(date, label = TRUE),
trimestre = quarter(date),
semaine = week(date),
jour_semaine = wday(date, label = TRUE, week_start = 1),
jour_mois = day(date),
weekend = ifelse(wday(date) %in% c(1, 7), "Weekend", "Semaine"),
saison = case_when(
month(date) %in% c(12, 1, 2) ~ "Hiver",
month(date) %in% c(3, 4, 5) ~ "Printemps",
month(date) %in% c(6, 7, 8) ~ "Été",
TRUE ~ "Automne"
)
)
# Structure des données enrichies
glimpse(ventes_enrichies)Rows: 730
Columns: 11
$ date <date> 2023-01-01, 2023-01-02, 2023-01-03, 2023-01-04, 2023-01-…
$ ventes <dbl> 10445, 8780, 10574, 9091, 9154, 10745, 11496, 9775, 8358,…
$ magasin <chr> "Paris", "Bordeaux", "Lille", "Lyon", "Paris", "Bordeaux"…
$ annee <dbl> 2023, 2023, 2023, 2023, 2023, 2023, 2023, 2023, 2023, 202…
$ mois <ord> janv, janv, janv, janv, janv, janv, janv, janv, janv, jan…
$ trimestre <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ semaine <dbl> 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, …
$ jour_semaine <ord> dim\., lun\., mar\., mer\., jeu\., ven\., sam\., dim\., l…
$ jour_mois <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17…
$ weekend <chr> "Weekend", "Semaine", "Semaine", "Semaine", "Semaine", "S…
$ saison <chr> "Hiver", "Hiver", "Hiver", "Hiver", "Hiver", "Hiver", "Hi…Analysons maintenant l’évolution mensuelle des ventes :
# Ventes mensuelles
ventes_mensuelles <- ventes_enrichies %>%
group_by(annee, mois) %>%
summarise(ventes_totales = sum(ventes)) %>%
ungroup()
# Visualisation
ggplot(ventes_mensuelles, aes(x = mois, y = ventes_totales, fill = factor(annee))) +
geom_col(position = "dodge") +
scale_y_continuous(labels = label_number(suffix = " €", big.mark = " ")) +
labs(
title = "Ventes mensuelles par année",
x = "Mois",
y = "Ventes totales",
fill = "Année"
) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))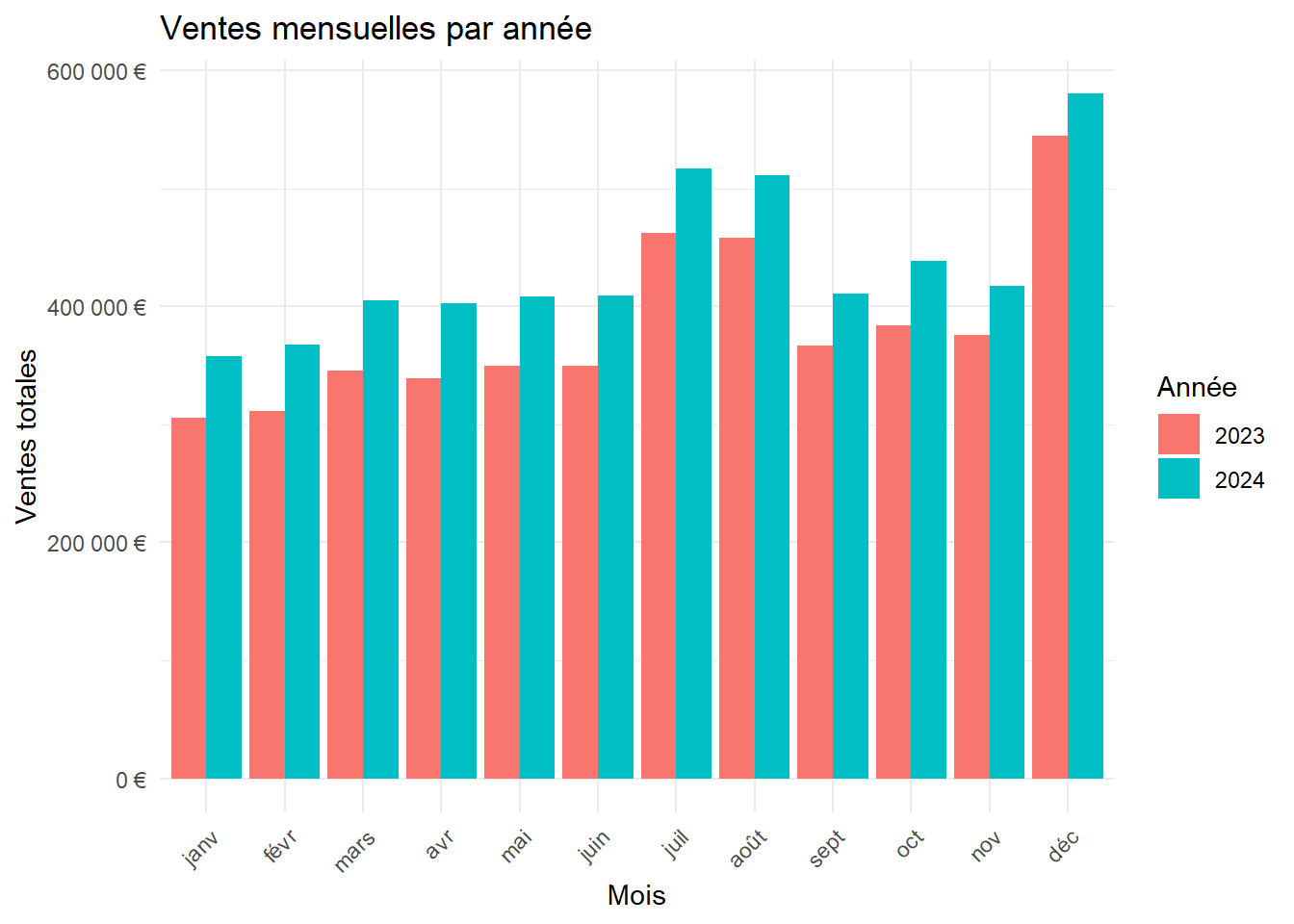
# Ventes par jour de semaine
ventes_jour_semaine <- ventes_enrichies %>%
group_by(jour_semaine, weekend) %>%
summarise(ventes_moyennes = mean(ventes)) %>%
ungroup()
# Visualisation
ggplot(ventes_jour_semaine, aes(x = jour_semaine, y = ventes_moyennes, fill = weekend)) +
geom_col() +
scale_y_continuous(labels = label_number(suffix = " €", big.mark = " ")) +
labs(
title = "Ventes moyennes par jour de la semaine",
x = "Jour",
y = "Ventes moyennes",
fill = "Type de jour"
) +
theme_minimal()
# Ventes par saison et par année
ventes_saison <- ventes_enrichies %>%
group_by(annee, saison) %>%
summarise(ventes_totales = sum(ventes)) %>%
ungroup()
# Réordonner les saisons
ventes_saison$saison <- factor(ventes_saison$saison,
levels = c("Printemps", "Été", "Automne", "Hiver"))
# Visualisation
ggplot(ventes_saison, aes(x = saison, y = ventes_totales, fill = factor(annee))) +
geom_col(position = "dodge") +
scale_y_continuous(labels = label_number(suffix = " €", big.mark = " ")) +
labs(
title = "Ventes totales par saison",
x = "Saison",
y = "Ventes totales",
fill = "Année"
) +
theme_minimal()
# Ventes mensuelles par magasin
ventes_magasin <- ventes_enrichies %>%
group_by(annee, mois, magasin) %>%
summarise(ventes_totales = sum(ventes)) %>%
ungroup()
# Fusion année-mois pour la visualisation
ventes_magasin <- ventes_magasin %>%
mutate(periode = ymd(paste0(annee, "-", as.numeric(mois), "-01")))
# Visualisation
ggplot(ventes_magasin, aes(x = periode, y = ventes_totales, color = magasin)) +
geom_line() +
geom_point() +
scale_x_date(date_labels = "%b %Y", date_breaks = "2 months") +
scale_y_continuous(labels = label_number(suffix = " €", big.mark = " ")) +
labs(
title = "Évolution des ventes par magasin",
x = "Période",
y = "Ventes totales",
color = "Magasin"
) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
Analysons les jours de vente exceptionnels :
# Calcul des jours exceptionnels (ventes supérieures à la moyenne + 2 écarts-types)
moyenne_ventes <- mean(ventes_enrichies$ventes)
ecart_type_ventes <- sd(ventes_enrichies$ventes)
seuil_exceptionnel <- moyenne_ventes + 2 * ecart_type_ventes
jours_exceptionnels <- ventes_enrichies %>%
filter(ventes > seuil_exceptionnel) %>%
arrange(desc(ventes))
# Affichage des 10 meilleurs jours de vente
knitr::kable(
head(jours_exceptionnels %>%
select(date, jour_semaine, mois, ventes, magasin), 10),
caption = "Top 10 des jours de vente exceptionnels",
format.args = list(big.mark = " ")
)| date | jour_semaine | mois | ventes | magasin |
|---|---|---|---|---|
| 2024-12-15 | dim. | déc | 22 016 | Marseille |
| 2024-12-28 | sam. | déc | 21 829 | Marseille |
| 2024-12-29 | dim. | déc | 20 912 | Lyon |
| 2023-12-30 | sam. | déc | 20 845 | Bordeaux |
| 2024-12-07 | sam. | déc | 20 824 | Lille |
| 2023-12-31 | dim. | déc | 20 643 | Marseille |
| 2024-12-30 | lun. | déc | 20 636 | Paris |
| 2024-12-14 | sam. | déc | 20 483 | Marseille |
| 2023-12-09 | sam. | déc | 20 386 | Paris |
| 2023-12-26 | mar. | déc | 20 371 | Bordeaux |
# Intervalles entre jours exceptionnels
jours_pic <- jours_exceptionnels %>%
arrange(date) %>%
pull(date)
# Calcul des intervalles (en jours)
intervalles <- diff(jours_pic)
# Statistiques sur les intervalles
resume_intervalles <- data.frame(
intervalle_min = min(intervalles),
intervalle_median = median(intervalles),
intervalle_moyen = mean(intervalles),
intervalle_max = max(intervalles)
)
knitr::kable(resume_intervalles,
caption = "Statistiques sur les intervalles entre pics de vente (en jours)")| intervalle_min | intervalle_median | intervalle_moyen | intervalle_max |
|---|---|---|---|
| 1 days | 1 days | 11.72727 days | 188 days |
Nous pouvons utiliser lubridate pour extrapoler les ventes futures en nous basant sur les patterns saisonniers identifiés :
# Création de dates futures pour prévision
dates_futures <- seq(max(ventes$date) + days(1),
max(ventes$date) + days(30), by = "day")
# Préparation du dataframe pour les prévisions
previsions <- data.frame(
date = dates_futures,
jour_semaine = wday(dates_futures, label = TRUE),
mois = month(dates_futures, label = TRUE),
jour_mois = day(dates_futures)
)
# Application des facteurs saisonniers identifiés
previsions <- previsions %>%
mutate(
facteur_weekend = ifelse(wday(date) %in% c(1, 7), 1.2, 1),
facteur_fin_mois = ifelse(jour_mois >= 25, 1.1, 1),
facteur_mois = case_when(
mois %in% c("juil.", "août") ~ 1.3,
mois == "déc." ~ 1.5,
mois == "janv." ~ 0.9,
TRUE ~ 1
),
ventes_prevues = 15000 * facteur_weekend * facteur_fin_mois * facteur_mois
)
# Aperçu des prévisions
knitr::kable(
head(previsions %>%
select(date, jour_semaine, ventes_prevues), 10),
caption = "Prévision des ventes pour les 10 prochains jours",
format.args = list(big.mark = " ")
)| date | jour_semaine | ventes_prevues |
|---|---|---|
| 2024-12-31 | mar. | 16 500 |
| 2025-01-01 | mer. | 15 000 |
| 2025-01-02 | jeu. | 15 000 |
| 2025-01-03 | ven. | 15 000 |
| 2025-01-04 | sam. | 18 000 |
| 2025-01-05 | dim. | 18 000 |
| 2025-01-06 | lun. | 15 000 |
| 2025-01-07 | mar. | 15 000 |
| 2025-01-08 | mer. | 15 000 |
| 2025-01-09 | jeu. | 15 000 |
# Calcul des moyennes mobiles sur 7 jours
ventes_moyennes_mobiles <- ventes %>%
arrange(date) %>%
mutate(
ventes_moy_7j = zoo::rollmean(ventes, k = 7, fill = NA, align = "right"),
periode_debut = date - days(6),
periode_fin = date
)
# Visualisation des dernières 30 observations
tail_ventes <- tail(ventes_moyennes_mobiles, 30)
ggplot(tail_ventes, aes(x = date)) +
geom_line(aes(y = ventes), color = "gray50") +
geom_line(aes(y = ventes_moy_7j), color = "blue", size = 1) +
scale_y_continuous(labels = label_number(suffix = " €", big.mark = " ")) +
labs(
title = "Ventes quotidiennes vs. moyenne mobile sur 7 jours",
subtitle = "30 derniers jours d'observation",
x = "Date",
y = "Ventes"
) +
theme_minimal()
# Identification des jours où les ventes dépassent 20 000 €
jours_20k <- ventes %>%
filter(ventes > 20000) %>%
arrange(date) %>%
pull(date)
# Calcul des intervalles entre ces jours
intervalles_20k <- data.frame(
date_debut = head(jours_20k, -1),
date_fin = tail(jours_20k, -1),
intervalle = as.numeric(diff(jours_20k))
)
# Affichage des 5 premiers intervalles
knitr::kable(
head(intervalles_20k, 5),
caption = "Intervalles (en jours) entre les ventes dépassant 20 000 €"
)| date_debut | date_fin | intervalle |
|---|---|---|
| 2023-12-09 | 2023-12-26 | 17 |
| 2023-12-26 | 2023-12-30 | 4 |
| 2023-12-30 | 2023-12-31 | 1 |
| 2023-12-31 | 2024-12-07 | 342 |
| 2024-12-07 | 2024-12-14 | 7 |
Définissons des saisons commerciales personnalisées et analysons les performances :
# Définition des périodes commerciales
periodes_commerciales <- function(date) {
case_when(
(month(date) == 11 & day(date) >= 25) |
(month(date) == 12 & day(date) <= 31) ~ "Fêtes de fin d'année",
(month(date) >= 6 & month(date) <= 8) ~ "Période estivale",
(month(date) >= 1 & month(date) <= 2) ~ "Soldes d'hiver",
(month(date) >= 6 & month(date) <= 7 & day(date) <= 15) ~ "Soldes d'été",
TRUE ~ "Période normale"
)
}
# Application à nos données
ventes_periodes <- ventes %>%
mutate(periode_commerciale = periodes_commerciales(date))
# Analyse des ventes par période commerciale
resume_periodes <- ventes_periodes %>%
group_by(periode_commerciale) %>%
summarise(
ventes_totales = sum(ventes),
ventes_moyennes = mean(ventes),
nb_jours = n()
) %>%
arrange(desc(ventes_moyennes))
# Visualisation
knitr::kable(
resume_periodes,
caption = "Performance des ventes par période commerciale",
format.args = list(big.mark = " ")
)| periode_commerciale | ventes_totales | ventes_moyennes | nb_jours |
|---|---|---|---|
| Fêtes de fin d’année | 1 295 373 | 17 744.84 | 73 |
| Période estivale | 2 707 913 | 14 716.92 | 184 |
| Période normale | 4 472 982 | 12 635.54 | 354 |
| Soldes d’hiver | 1 341 800 | 11 275.63 | 119 |
# Exemples de formatage
ma_date <- ymd("2025-02-25")
formats <- c(
"%d/%m/%Y",
"%A %d %B %Y",
"%d %b %Y",
"Semaine %U, %Y"
)
# Application des différents formats
formats_affiches <- sapply(formats, function(fmt) format(ma_date, fmt))
# Affichage des résultats
data.frame(
Format = formats,
Résultat = formats_affiches
) Format Résultat
%d/%m/%Y %d/%m/%Y 25/02/2025
%A %d %B %Y %A %d %B %Y mardi 25 février 2025
%d %b %Y %d %b %Y 25 févr. 2025
Semaine %U, %Y Semaine %U, %Y Semaine 08, 2025# Création d'une date avec heure et fuseau horaire
date_paris <- ymd_hms("2025-02-25 14:30:00", tz = "Europe/Paris")
date_paris[1] "2025-02-25 14:30:00 CET"# Conversion vers d'autres fuseaux horaires
date_ny <- with_tz(date_paris, tzone = "America/New_York")
date_tokyo <- with_tz(date_paris, tzone = "Asia/Tokyo")
# Comparaison
data.frame(
Ville = c("Paris", "New York", "Tokyo"),
Heure_locale = c(
format(date_paris, "%H:%M:%S"),
format(date_ny, "%H:%M:%S"),
format(date_tokyo, "%H:%M:%S")
),
Date = c(
format(date_paris, "%d %b %Y"),
format(date_ny, "%d %b %Y"),
format(date_tokyo, "%d %b %Y")
),
Fuseau = c(tz(date_paris), tz(date_ny), tz(date_tokyo))
) Ville Heure_locale Date Fuseau
1 Paris 14:30:00 25 févr. 2025 Europe/Paris
2 New York 08:30:00 25 févr. 2025 America/New_York
3 Tokyo 22:30:00 25 févr. 2025 Asia/Tokyo# Exemple de dates avec valeurs manquantes
dates_avec_na <- c("2025-02-25", NA, "2025-03-01")
dates_parsees <- ymd(dates_avec_na)
dates_parsees[1] "2025-02-25" NA "2025-03-01"# Vérification des NA
is.na(dates_parsees)[1] FALSE TRUE FALSE# Filtrage des NA
dates_parsees[!is.na(dates_parsees)][1] "2025-02-25" "2025-03-01"Le package lubridate offre une approche intuitive et puissante pour manipuler les dates en R, ce qui est essentiel pour l’analyse de données commerciales. Voici quelques bonnes pratiques à retenir :
period et duration selon vos besoinsinterval, time_length, etc.)ymd(), dmy(), mdy()year(), month(), day(), wday()+ days(), + months(), + years()interval(), as.period(), time_length()round_date(), floor_date(), ceiling_date()Maîtriser ces fonctions vous permettra d’analyser efficacement la dimension temporelle de vos données commerciales et d’en extraire des insights précieux pour votre entreprise.
tsibble pour les séries temporelles, timetk pour l’analyse temporelle avancée